In Depth DHCP and Network Connectivity Troubleshooting
I recently spent over two and a half days troubleshooting a very hard to track down issue. It was reported to me that users were experiencing extended network disconnects when undocking and switching between wifi and wired network, mainly when swapping from docked and wired to wireless. The issues were reported as consistent and reproduceable and at that time that is all of the information I knew. I will walk through the troubleshooting steps that I took and how I discovered what the issue was, and what was done to fix it.
TL;DR
IP device tracking running on a Cisco switch would send ARP probes to devices in the middle of the DHCP process and it would interpret the packet as a device on the network having a duplicate IP address and decline the address. This caused the device to self-assign an APIPA address and would have a drop in network communication until it successfully was able to get an IP address without interference from IP Device tracking on the switch. This was fixed by setting a 10 second delay on IP Device tracking on the switches in the network.
Additional Context
- Laptops were HP
- Docks are USB and various manufactures
- Laptops do not have consistent BIOS firmware
- Wired and wireless networks are on different subnets connected to a Cisco Nexus core
Gathering Data
I first went to the site and tried recreating the issue on my laptop by docking and undocking various times and I noticed that I would miss 1 ping when going from wired to wireless but intermittently it would take a minute to swap from wireless to wired and for that minute all network communications would stop.
Talking with Affected Users
I then went to the affected users and asked them to explain the issue and see if we could reproduce it there. Everyone reported that the issues were from wired to wireless however we were unable to replicate the issues when attempting at that time. There was 1 user that allowed me to spend over an hour with them trying to reproduce the issue and come to find out I was able to consistently able to reproduce the extended outage going from wireless to wired within 6 undock/redock cycles. I also noticed the NIC would get a different IP address each time I replicated the issue.
Looking at the DHCP server when replicating the issue, the computers previous IP address would be marked as "BAD ADDRESS" and they would get a new one. This was consistent.
Could be a Rogue DHCP Server
My first thought was a Rogue DHCP server on the wired subnet so I fired up wireshark on a device and threw some filters on checking for DHCP replies from anything other than the known DHCP servers. I released and renewed the devices address over 5 times and did not get any replies for any server other than our known DHCP servers.
It was not a rogue DHCP server.
Plot Thickens
I cleared out all the bad addresses from the DHCP server and tried to reproduce the issue and after 15 dock/redock cycles was unable to replicate the issue. Went to a different switch in the building and still unable to reproduce the issue. Then after coming back to the initial switch we finally got it to reproduce again. looking It was the end of the day so the plan the following day was to bring all dock and laptop types and see if it is a dock or laptop model that is consistent.
Next Day
I arrived early and tested with other hardware and was able to consistently reproduce the issue every 6 dock/redocks on average of various hardware types.
It was not a computer/dock hardware thing
I then started wiresharking at various points of the network wanting to get an in depth look at the DHCP request lifecycle to see if packets were getting dropped when the request was being forwarded to the DC.
Wiresharking the uplink and replicating the issue I was seeing a Request --> ACK --> Decline when I saw that I thought there must be a device out there with a duplicate IP address, or a device that is incorrectly thinking it has a duplicate address and replying to the devices ARP request.
This could be due to proxy-arp being configured on a router inside of that subnet, I figured that would be more likely at this time becuase there were so many bad addresses in the DHCP server, the odds of having that many incorrectly statically assigned devices in my environment was unlikely.
Because I was wiresharking the uplink on the WAN side I was not seeing the ARP requests so this time I mirrored the switchport that my test machine was on to the switchport of my capture machine.
When watching the traffic I was seeing Request --> Ack --> Arp Probe from my machine for assigned address --> Decline Then I was very confused because there was not any response that any other device on the network had my IP address.
Why Would Windows be Declining IP Addresses
After some research I found a Cisco article which also linked to RFC 5227 which stated that back in the Windows Vista days that RFC was put into windows IP conflict detection which caused issues with Cisco networks running IP device tracking.
The reason for that is that because of that RFC after windows gets its address, there is a 10 second window that if Windows receives an ARP request from IP 0.0.0.0 that is requesting information for the IP the Windows machine has been offered and that ARP request has a source MAC address that is different from the MAC address of its NIC, it will assume that the address it has been given is a duplicate and will deny the IP address and the server will record it as a BAD ADDRESS. Cisco's IP Device tracking sends ARP probes with that exact description so if one is sent during that 10 second window it will cause an extended outage for that device trying to get an IP address because it will self assign an APIPA address and have to go through the process again.
I have IP Device tracking setup on the switches. It has to be this!
Revisiting the Wireshark Captures
Sure enough I look at the Wireshark capture and I have a DHCP request to extend the lease time, an ACK from the server, and ARP probe from my test machine for the IP it was provided, and less than 10 seconds later an ARP probe from the switch with a source IP address of 0.0.0.0 and a source MAC of the switch (Not my test machine) and then a DHCP Decline from my test machine.
Below I have the sequence of packets I described above. Highlighted in black is packet #134 which is the IP device tracking packet from the switch which caused the Windows computer to decline the DHCP address. Notice the Source MAC is the Cisco device, it is requesting information on 10.200.100.88 which was provided to my Windows computer, and it is coming from IP 0.0.0.0 (Tell 0.0.0.0 in the info column).
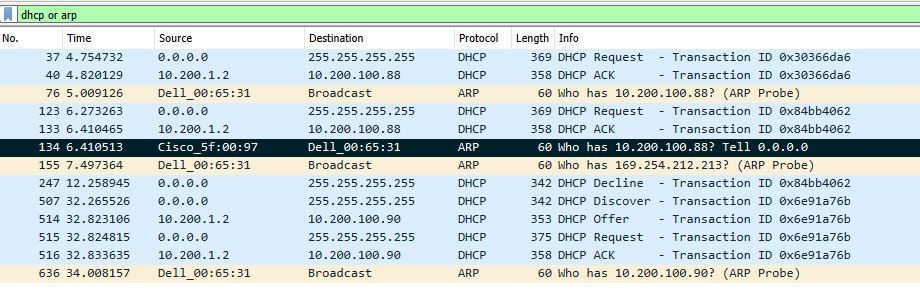
Then packet 247 is the DHCP decline.
I Found the Issue
Per the Cisco article linked above the suggestion is to set the IP device tracking probe delay to 10 seconds (default configuration is no delay) and it will solve the issue.
On all switches in that network I set the probe delay to 10 seconds
switch(config)#ip device tracking probe delay 10I have yet to have any more BAD ADDRESS entries in my DHCP server and most importantly connectivity during docking/undocking cycles improved according to the people that were having an issue and by my tests.
This was one of the weirder issues I have had to troubleshoot in a while. Unfortunately, the information provided by the end users was not accurate. Specifically, undocking and going from wired to wireless and having network connectivity issues was NEVER reproduced even after over 400 dock/undock cycles.
Takeaways
There are a few takeaways from this process to bring into the future.
- Never assume that because something has been setup and working for a while that it couldn't be causing the issue
- IP device tracking has been setup for years at this organization however because laptops are relatively new and the issue appears to happen with laptops on docks vs devices with integrated NIC's so the issue appeared years down the line
- When setting up Wireshark captures start at one logical end and move to the other, or setup multiple in the chain right away.
- I could have captured all the data needed right away if I setup the capture directly on the workstation versus starting on the WAN side.
- While I was looking for something specific at the time and now with the benefit of hindsight its clear it would have saved time by starting on the machine, its a good idea to take that knowledge into the future.
- Have 1 or multiple machines available that can be used to Wireshark a problem.
- I found myself apprehensive about starting up a Wireshark capture because of the extra work it takes to procure hardware and get everything setup.
- There should be a relatively easy way of Wiresharking any place on the network by plugging a machine in and entering a few commands.
- Additionally the Wireshark device should be capable of being remoted into it while capturing on a spanned port so you are not required to be in the same physical place to start/stop/analyze/transfer a packet capture.